随机森林回归
原理描述
本工具使用python语言包scikit-learn和NumPy建立随机森林模型。
用法
点击机载林业 > 回归分析 > 随机森林。
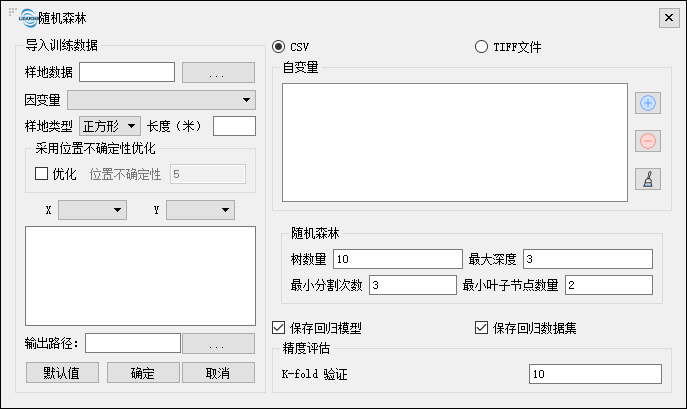
参数设置
- 导入训练数据:参考样本数据和自变量。
- 自变量:参考样本数据和自变量。
- 样地类型:正方形:选择样本临近的矩形区域内的点;圆形选择样本临近的圆形区域内的点。
- 长度:样地类型查询的半径。
- 采用位置不确定性优化:勾选优化后,位置不确定性变为可设置状态,该位置不确定性中的数值表示范围查询的精度值,模型内部根据该范围查询所有满足条件的样本点(样本点数如果超过50,会选择前50个点作为样本),然后根据这些样本点选择模型最优的点作为分析数据;不勾选优化,位置不确定性变为不可设置状态,模型内部会根据样本点选择最近点作为分析数据。
- 随机森林:该参数定义了随机森林的参数值。
- 树个数:随机森林模型中的树数量。
- 最大深度:随机森林模型中最大深度。
- 最小分割次数:随机森林模型中最小分割次数。
- 最小叶子节点数:随机森林模型中最小叶子节点数量。
- 精度评价:采用K-Fold交叉评价模型,根据输入的K-Fold参数,将样本分为K类,依次取其中一份作为测试数据,其它作为训练数据进行模型训练,用测试数据进行测试,选择出误差最小的模型作为最佳模型进行使用,注意:K-Fold值必须大于等于2。
- 保存回归模型:选择框被勾选,程序成功运行后将会在输出路径输出(随机森林回归.model)model模型。
- 保存回归数据集:选择框被勾选,程序成功运行后将会在输出路径输出(随机森林回归.csv)训练数据模型csv格式文件。
- 输出路径:选择输出的文件目录地址,在程序成功运行后,会生成相应的模型报告(随机森林回归.html)文件,其中记录了模型的误差和相关值;生成相应的结果文件(随机森林回归.tif),该文件是根据模型计算出导入的tif或者csv文件的自变量值,预测出相应的因变量生成的结果;并根据勾选情况,选择生成回归模型和数据集。
- 默认值:将参数恢复默认值。
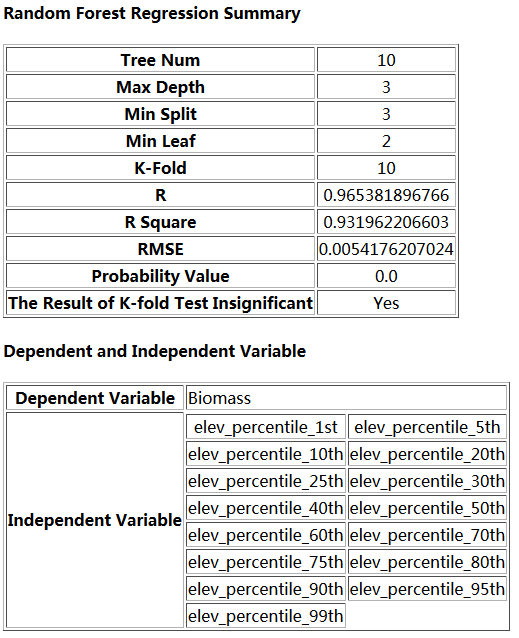
注意:导入的样本数据必须包含在导入的自变量数据范围中,自变量可以根据实际情况进行添加或者删除,最终结果文件是根据传入的自变量信息生成的,最大深度和树个数要大于0。