基于树木位置的自动配准
功能概述
此功能利用两块点云的树木位置进行自动配准(Guan H , Su Y , Hu T , et al., 2019)。树木位置储存在一个逗号分隔的CSV表格文件中,该文件需要包含至少两个字段:TreeLocationX 和 TreeLocationY,该文件格式可参考CHM分割结果文件格式。配准矩阵的求解将分解为水平方向和垂直方向。对于水平方向配准,将利用各个单木的x、y坐标建立特征描述子,进而寻找匹配点,最后基于匹配点求解水平方向旋转矩阵;对于垂直方向配准,首先取得单木邻域范围内的点云,然后利用点云中的最大值或最小值寻找Z方向的偏移量。 配准的成功率取决于待配准点云与配准点云相应的单木位置的匹配程度,匹配程度越高,则算法成功率越高。单木匹配程度取决于数据重叠度、位置精确程度等。
用法
点击 数据管理 > 点云工具 >基于树木位置的自动配准
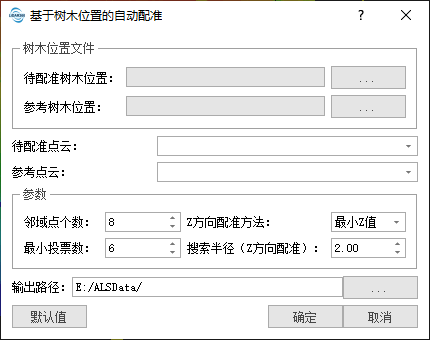
参数设置
- 参考点云: 参考点云数据。经配准后,待配准点云将被配准到参考点云坐标系下。
- 待配准点云:待配准点云。配准后,旋转平移矩阵将应用到待配准点云上,并生成配准后的新文件。
- 邻域点个数(默认为8):在单木周围构建特征描述子时采用的邻域大小。邻域点个数的增加会提升算法的时间复杂度,同时使匹配点的描述子更加健壮;邻域点个数减少时,提升算法效率,但会使局外匹配点个数增多。此值宜设置为8~12。
- 最小投票数(默认为6):低于此票数的单木位置将被认为是局外点,不参与匹配。此值越小,将得到更多配点,但匹配点对的误差也会越大。此值越大,所得匹配点越少,过大时将导致没有足够多的匹配点进行矩阵计算。邻域点个数增加时,可以适当提高此值。此值宜设置为6~9。
- 单应性矩阵反投影误差(默认为3.0):单应性矩阵的反投影误差。候选点的筛选采用单应性矩阵结合Ransac算法进行。反投影误差越小,所筛选出的单木匹配点数量越少、匹配程度越高。此值越大,匹配点的筛选条件越宽松,匹配点对的误差越大;而此值过小时,可能导致没有足够多的匹配点参与计算。此值宜设置为2~4最为适宜。
- 搜索半径(默认为2.0):进行Z方向配准时,邻域搜索采用的搜索半径大小。进行Z方向配准时,需寻找各个单木在XY平面上一定邻域范围内的真实点云,然后利用真实点云的坐标进行配准。此值过大或过小时,点云都将无法描述真实的地形起伏状况。此值宜设置为1.0~3.0,过大时将导致算法效率降低。
- 平移Z值(默认采用“最小值”):Z方向配准方法有两种,分别为“最大值”和“最小值”。此值描述的是,对单木位置进行半径搜索后,取邻域内点云的“最大/小值”作为真实匹配点,用于计算最终的Z方向平移量。使用“最大值”时,需保证单木附近的树梢点云不存在缺失或扭曲,否则将无法从点云中提取出准确的匹配点。使用“最小值”时,需保证单木附近有足够地面点,否则将导致Z方向匹配失败。
@inproceedings{
author={Guan H , Su Y , Hu T , et al.},
title={ A Novel Framework to Automatically Fuse Multiplatform LiDAR Data in Forest Environments Based on Tree Locations},
booktitle={IEEE Transactions on Geoence and Remote Sensing},
year={2019},
}